Last fall, my attendance at the SQL Summit was entirely justified by a presentation by Aaron Nelson, a SQL Server MVP on Excel, PowerShell and SQL Server.
Unfortunately, I regularly suffer from having Excel as a data source. In an ideal world, this wouldn’t happen.
Logically, no one would buy a SaaS solution without first figuring out how the data in that system would be accessed and combined with all the other data your organization needs.
Unfortunately, things aren’t always logical.
Too many SaaS solutions provide no way for you to get the data except through creating reports (or worse, using prepackaged reports) which can be dumped into Excel or csv format.
There are many potential issues with this approach.
I’m in the process of preparing my own in depth presentation on this topic, which has led me to write this series of blog posts.
In this series (and in my future presentation) I hope to address as many of the pitfalls as possible.
Personally, I hate blog posts that merely show everything going right. So I’ll be showing you how wonderfully it works—but also how many things can go wrong.
Why You Don’t Want to Use OPENROWSET with Excel
Some of you who have stumbled upon this blog post may wonder why you would even need PowerShell to get data from Excel to SQL Server.
Doesn’t T-SQL let you do this directly? I get it. I’m a T-SQL person and the older I get the fewer new things I want to learn if I don’t have to.
And indeed, it does seems to. If we start with a simple spreadsheet like this:
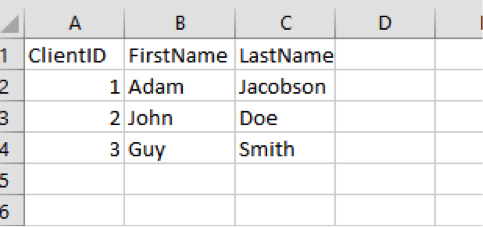
We can simply load it using the following command:
SELECT *
FROM OPENROWSET('Microsoft.ACE.OLEDB.12.0',
'Excel 12.0 Xml;
Database=C:\Users\adam\OneDrive - Red Three Consulting, Inc\R and D\Blog Posts\2018-11-20 Loading Excel Data to PowerShell\010 - 1 - Working Spreadsheet.xlsx',
[Sheet1$])
Code language: SQL (Structured Query Language) (sql)So, what’s not to like? It turns out, quite a bit.
A few key issues:
- You need to have the Access driver installed on your server.
- You need to create a linked server—and sometimes you’ll need to make changes directly to the registry to get it to work.
- Once that’s done, you’ll have to make more setting changes to SQL Server (which your admin will love—not).
- When you’ve finally got it working, you may then stumble upon this little piece of Microsoft documentation:

I know all this from first hand experience.
The Basics: From Excel to SQL
For all of the following examples, we need to make sure we have two PowerShell modules installed. (For our purposes here, I’m going to assume you’re somewhat new to PowerShell.)
The two modules to install are:
- SQLserver
- ImportExcel.
(More on these in a minute.)
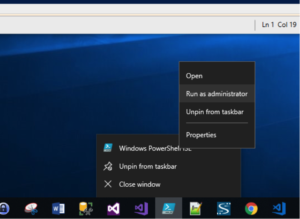
Please note, in order to install modules on PowerShell, we need to launch the PowerShell ISE (Integrated Scripting Environment) as administrator (see below):
This is all we’re going to have to install (i.e. we don’t need to install Excel).
However, we do need to set up two other pieces correctly:
- We need whatever database access we’re using to insert data to an existing table, to create table.
- We need bulk insert privileges, which need to be granted on the server.
Once we start PowerShell ISE, we need to enter the following commands to install the values we need:
install-module -name sqlserver
Install-Module -Name ImportExcel -RequiredVersion 5.4.2
Code language: CSS (css)The first module provides a wide range of commands to be used with SQL Server. We’ll be mostly interested in Write-SQLTableData (and to a lesser extent, Read-SQLTableData).
The other module, ImportExcel, is an open source project created by Doug Finke. If you use his stuff, you really should make a donation. It has saved me hours and hours of time.
This module allows you do to a wide range of things in Excel using PowerShell. I’ve only used it to read Excel sheets and write out some simple sheets. I’m not quite sure I understand the purpose of all the other use cases, but I have some built-in anti-Excel bias. But I digress.
Once these modules have been installed successfully, it’s best to leave the PowerShell ISE and sign in again without administrator privileges—just to be safe. (Nothing we do is going to change anything on your computer. But it’s always safest to make no assumptions.)
So, now we’re ready to go. Let’s start with a simple spreadsheet that we’re going to move into SQL Server.
Here’s the spreadsheet (again):
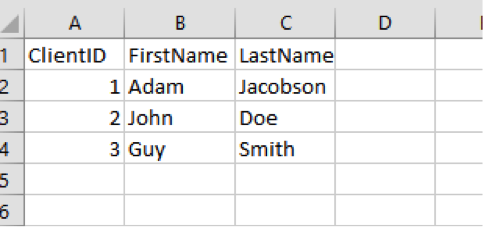
And here’s the code we need:
# Variables for Import-Excel
$FolderName = "C:\Users\adam\OneDrive - Red Three Consulting, Inc\R and D\Blog Posts\2018-11-20 Loading Excel Data to PowerShell"
$FileName = "010 - 1 - Working Spreadsheet.xlsx"
$FileNameWithFolder = join-path $FolderName $FileName
$FileNameWithFolder
#Variables for Write-SQLTableData
$SQLServerInstance = "ADAM2017"
$Database = "RedThree"
$SchemaName = "excel"
$TableName = "Example1"
,(Import-Excel -path $FileNameWithFolder -ErrorAction Stop) |
Write-SqlTableData -serverinstance $SQLServerInstance -DatabaseName $Database -SchemaName $SchemaName -TableName $TableName -force -ErrorAction Stop
Code language: PowerShell (powershell)When we run this, we see a brand new table on SQL Server with our data.
And voila, we’ve successfully:
- Read the spreadsheet.
- Loaded it into the database.
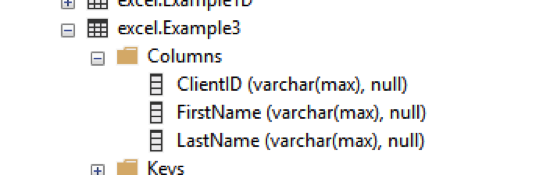
Along the way, we created a new table called excel.Example1.
Checking SQL Server, we see our data:
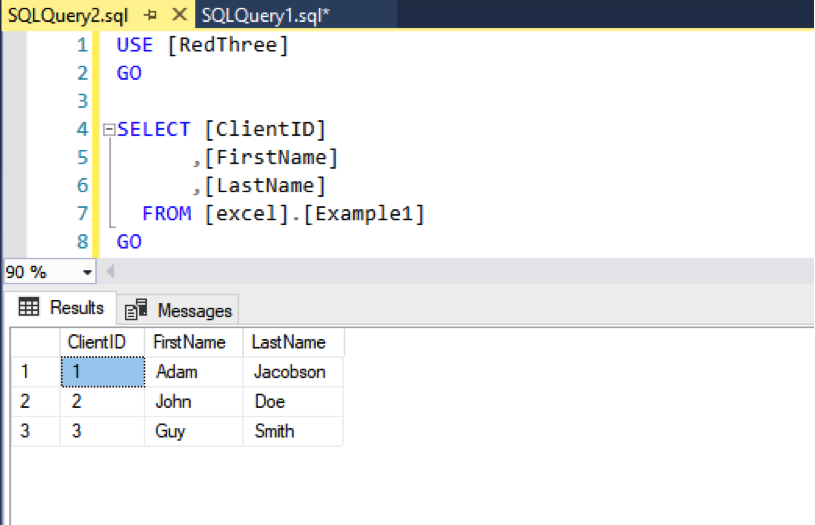
Looking at the Table definition, we will see that Write-SQLTableData can choose some strange variable types. (I mean, why “float”?):
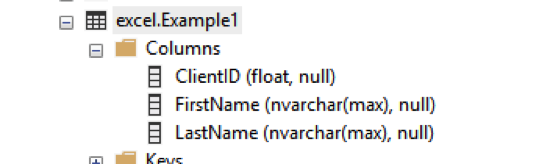
Often, I use the force option to get the table set up but then make changes to the table for my own use.
In this case, I altered the columns so they are all varchar(max).
If you’re curious, you can check the Query Store and see that SQL Server performed a bulk insert command. Here’s what I found:
insert bulk [RedThree].[excel].[Example1] ([ClientID] Float, [FirstName] NVarChar(max) COLLATE SQL_Latin1_General_CP1_CI_AS)
OK, lesson complete. You can continue on your way. Or maybe check out that cat video.
Looking at This Scenario in More Detail
However, if you want more details, let’s continue.
Let’s start by going step by step through this little script. The commands themselves are pretty self-explanatory.
The first command reads the Excel file:

The Pipe symbol then passes it to SQL Server:

Let’s look at some of the less obvious parts of the command.
The Comma at the Beginning
The comma changes the way PowerShell pipes data from the first command to the second command.
It tells PowerShell to complete the first command before sending data to the pipe. This improves the performance of Write-SQLTableData. Dramatically.
I’ve tested this on a 1000-record Excel sheet. With the comma, the load was almost instantaneous. Without a comma, it took about 15 seconds.
“-ErrorAction”
You’ll see this as an option in both commands.
It’s necessary for the proper handling of exceptions with any PowerShell command, not just with the ones we are using. I plan to cover error handling in another post.
“-force”
This tells SQL to create a table if a table with that name doesn’t already exist.
Looking at the Data in PowerShell
If we hadn’t sent the data directly to SQL Server with the pipe, we could have looked at it directly in PowerShell. But I usually want to deal with my data in SQL Server (that is the whole point of all this!).
However, it is helpful when testing to see what’s coming from Excel. This exercise also gives us a little lesson about PowerShell variables.
Let’s give it a try so we can see what happens.
In this case, we suck the data into a variable and then pass it to a grid. Note that this code uses the same variables used above:

And here’s what we see:
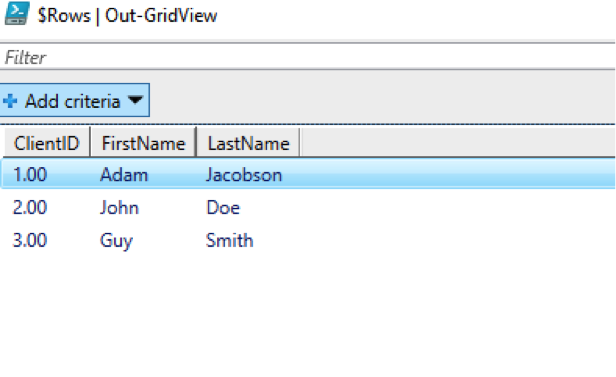
We can see that we have our columns from the spreadsheet.
What’s more interesting is that our array is special. Each “Row” of the array is actually a PowerShell Custom object having three properties: ClientID, FirstName, and LastName.
Therefore, we can treat each row and column from Excel as a row and property of the array of objects. Basically, each row is it’s own object and each column is a property of the object.
Let’s run this little code snippet:

When we do, we get the following output:
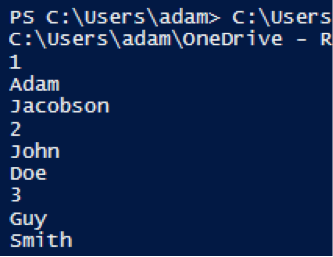
In our example of loading data, this might be useful if we wanted to only take certain columns from a given spreadsheet.
This might help you avoid issues where the underlying report changes without anyone telling you. However, I haven’t actually tried this in production.
Still, let’s try it with an example.
Let’s copy the rows from the sample Excel to a different array with only two of three columns. We then load it to SQL Server:

Switching over to SQL Server, we find this:
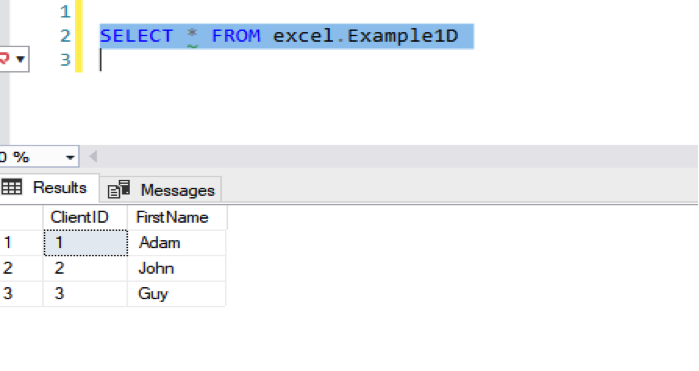
This methodology would also be useful for moving the file name and the load date into SQL Server.
What Could Possibly Go Wrong?
After months of struggling with OPENROWSET and bulk imports, I was thrilled when I finally got the above approach working. Now I use it every day.
But this is technology, so nothing is perfect. Things can go wrong.
Let’s look at some of them.
Problem #1: Write-SQLTableData Doesn’t (Always) Look at Your Column Names
When we used the -force option, we saw that Write-SQLTableData used the names in the first row of our spreadsheet in order to create the table. So, you might guess that it actually cares about those column names. Unfortunately, you would be wrong.
Let’s take our basic spreadsheet and swap the last name and first name columns:
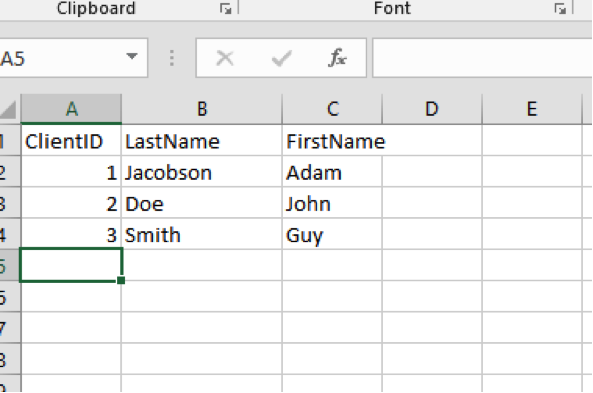
In our previous example, FirstName was column B and LastName was column A.
So, let’s bring this into our excel.Example1 table. (The syntax is the same as above so I won’t repeat it.)
When we check the data, we see the following:
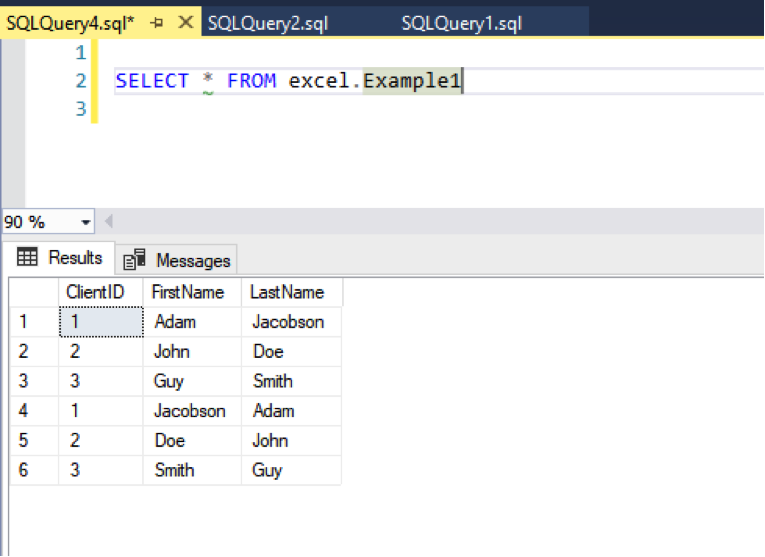
The first three rows are from our first example. Those make sense.
But the last three records went in by column order, not by column name. So “Jacobson” is now a first name.
Basically, once it finds a table it can use, Write-SQLTableData doesn’t look at your columns.
Problem #2: The Number of Excel Columns Doesn’t Match the Number of Columns in Your Table
What if we don’t have enough columns in our spreadsheet? Following the logic above, as long as the columns in your table accept null values, you’ll be fine:
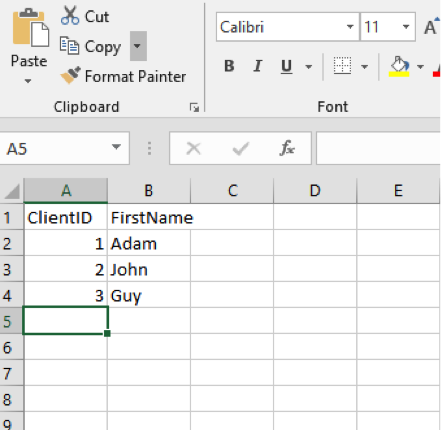
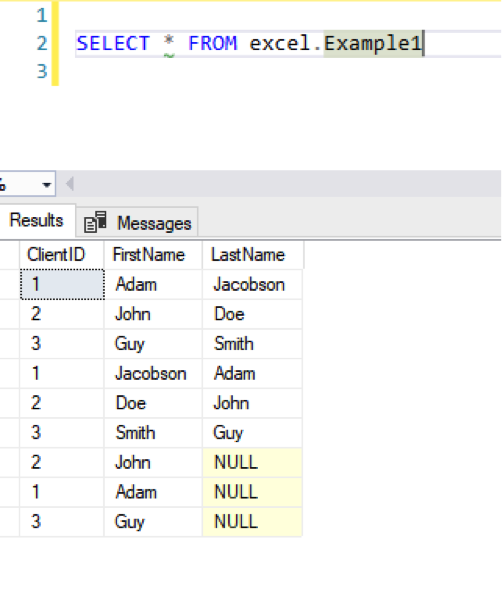
We load this into our excel.Example1 table (which has three columns), and we see that the last column is left null:
What if we have too many columns (as below)? Any guesses?
In this case, Write-SQLTableData gives us an error message:
“The given ColumnMapping does not match up with any column in the source or destination.”
Problem #3: Variable Type Checking (the Most Annoying Thing about Write-SQLTableData)
When we first created our table, we saw that Write-SQLTableData guessed at the types we wanted for each column.
In general, I make all my load table columns into varchar(max) and then deal with type issues in T-SQL. So, you’d think that variable typing wouldn’t be an issue in this stage. But you’d be wrong (again).
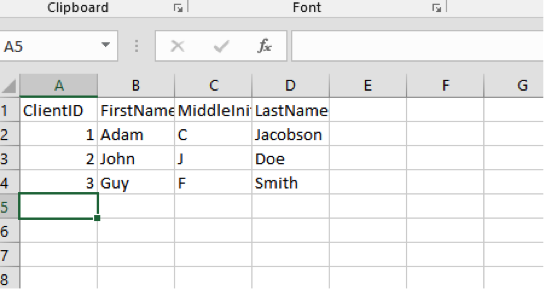
Here’s a small spreadsheet where the third record has a different type of ClientID:
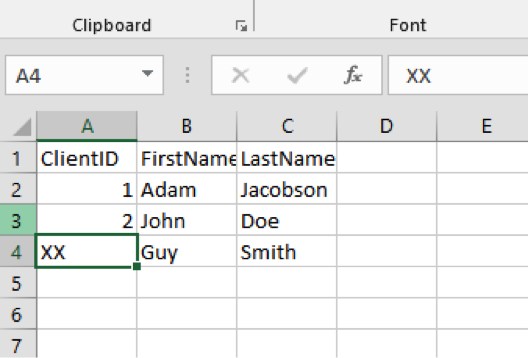
The table we’re using is set to VARCHAR(MAX) for all columns:
When we load the file, however, we receive the following error:
“Write-SqlTableData : Input string was not in a correct format. Couldn’t store <XX> in ClientID Column. Expected type is Double.”
What? Write-SQLTableData is trying to be helpful—it wants your data to be consistent even if the SQL Table itself doesn’t really care.
So, since the column starts out as double, it should remain as double. (Note that the type is driven by Excel. The field may look like an integer to you, but that’s just formatting in Excel.)
There are a couple of ways to solve this problem.
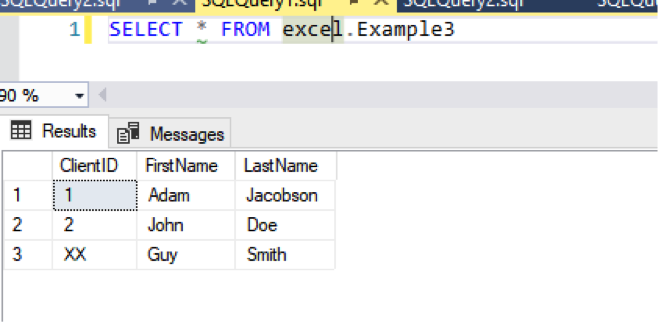
First, we can remove the comma from the beginning of the command. So, instead of this command:

We use this one:

And it actually works:
However, this can really, really slow down processing when we have a large file—as I noted earlier.
Another solution depends on how much you know about the “bad” value.
In general, (but only in general), report data is consistent. So, it’s not so much an issue of bad data in a column, as a superfluous row or two at the end. Like this:
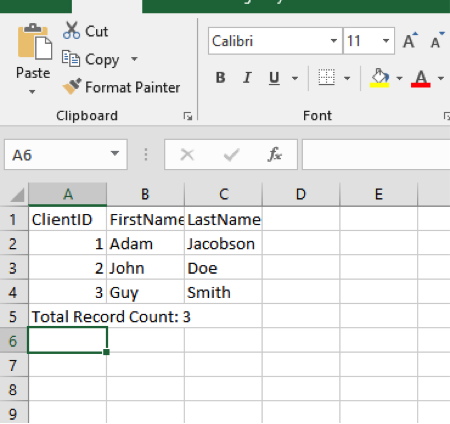
The first thing we can do is make sure every ClientID is actually a number before we pass it.
Remembering back to the example on selected columns, we basically take the array of objects we receive from Import-Excel and test the ClientID for each one before we move the object into an array that we’ll actually import.

The key line above is where we check that the client id is indeed the correct type.
This method works fine if we feel pretty confident about the issues we are going to have.
However, my general rule is to bring everything thing into SQL Server and deal with the issues there. So, I have another option.
PowerShell doesn’t care if you specify variable types. I’m not going to get into whether that’s a good or bad thing. For our purposes, it just is, and you can’t change that behavior.
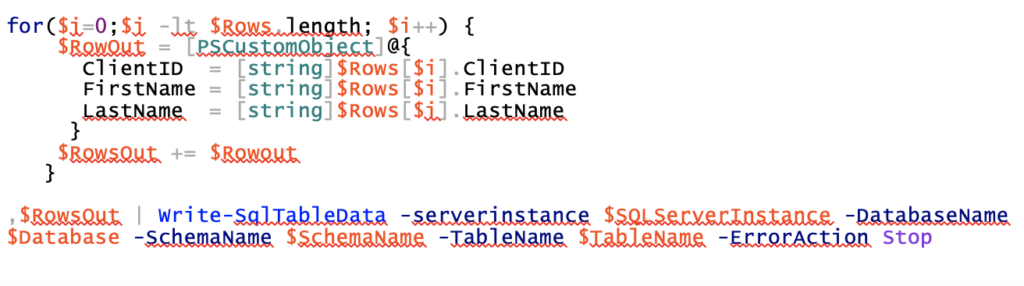
However, when preparing our array for import, we CAN specify types for each property. In our case, we want everything to be a string:
If we look at SQL Server, we see that even “Total Records” was loaded:
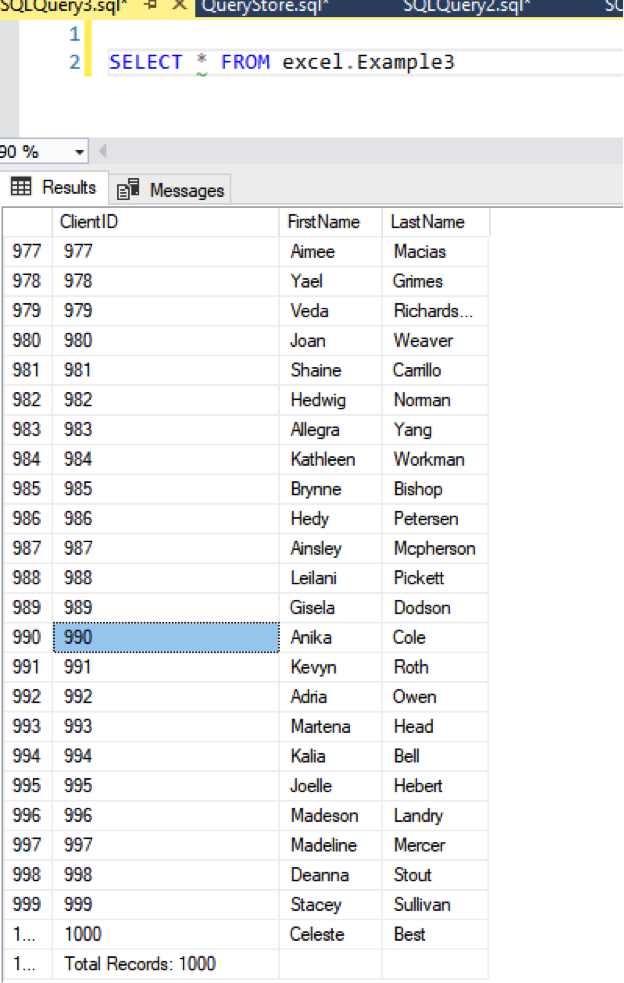
Of course, we’ll have to handle that “Total Records” entry in SQL Server.
Coming Next
I have more to say on this topic, but I’m going to save it for future posts.
Topics will include:
- Dates – All dates are not dates in Excel
- Error Checking
- Calling a stored procedure to actually move the data.